

 Investigation:
Investigation:
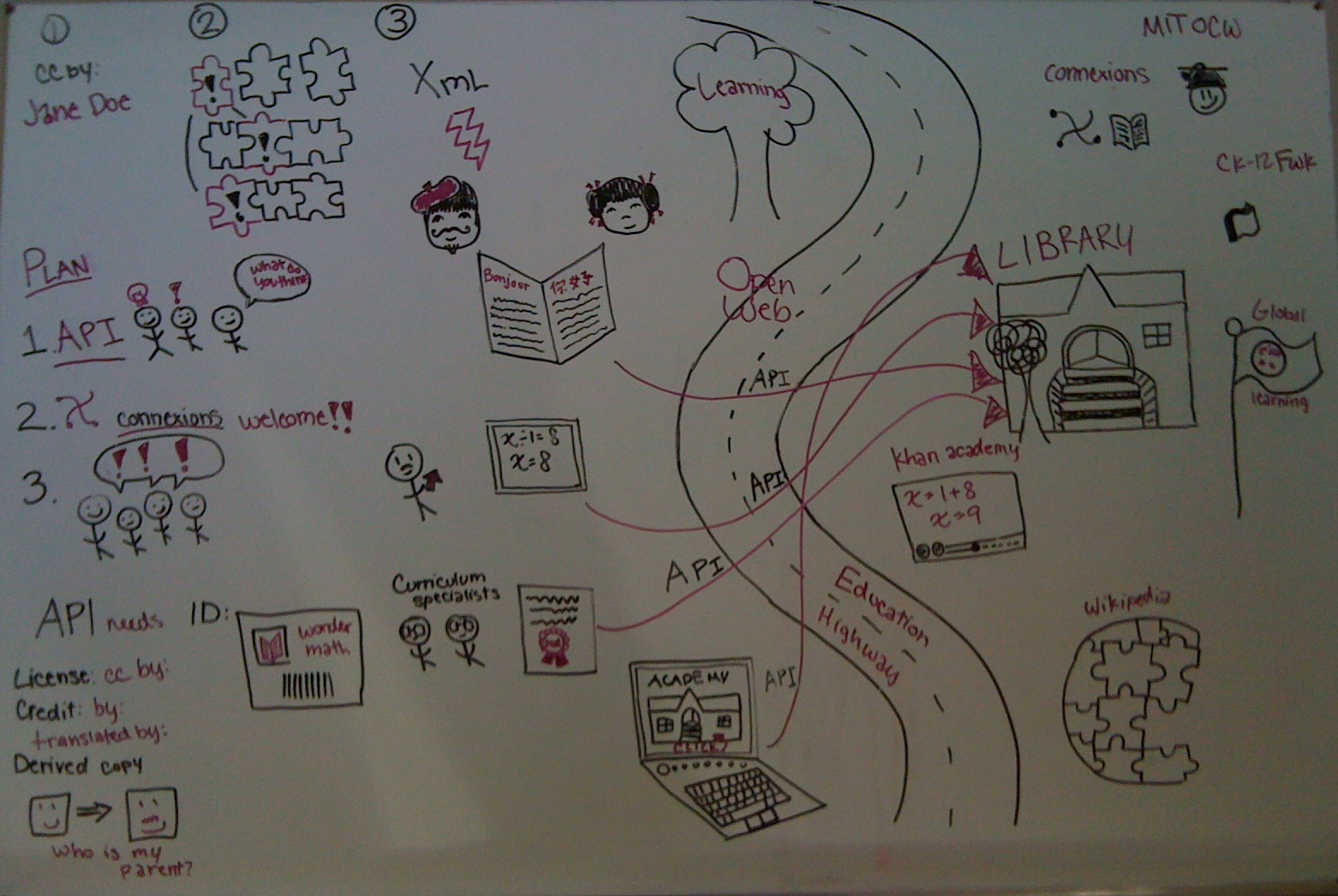
To start, it was important to look for an existing API to adapt for publishing OER that can support a learning ecosystem around open education repositories (especially delicious remixable ones). Like Goldilocks, I found a cottage in the woods with several to try. WebDAV, CMIS, and gdata are all interesting and well-established protocols for publishing to the web, but they are much too hot, or in other words they are either too complex for the task at hand, or too specific to particular services. Next I tried Atom Publishing Protocol, but unfortunately too cool — it was too general to specify the work flow natural to publishing packages of learning content. I found two bowls of very, very similar and tasty looking publishing APIs, called Simple Publishing Interface and Simple Webservice Offering Repository Deposit. The bowl I found most satisfying will become evident as the story unravels.
Birth of an OER Roadmap wiki and reserved parking spot for code (March 14): After some investigation of different hosting sites, I chose Google Code, because it had a lot of functionality that was easily available, and a very small learning curve. Welcome to OER-Roadmap.
Hewlett OER Grantees Meeting and Wikimedia: (Mar 29 – Apr 1) I went to the Hewlett’s annual OER grantees meeting and spent time reconnecting with old friends and meeting new ones regarding the broad goals of this fellowship and the potential to help catalyze education content production and consumption. After the grantees meeting I met with Erik Möller of Wikimedia about potential wikipedia/wikieducator bridges to Connexions and potentials for implementing the API in wikimedia projects.
I attended the NITLE Summit (April 6,7) where liberal arts college leaders think about education in a digital age. John Seeley Brown’s keynote (my notes here) on educating for change provided a though-provoking challenge regarding the kind of education needed when content changes constantly. I participated in the OER workshop led by Hal Plotkin of the US Department of Education.
Cataloging the current Connexions’ API: (April 14th on) : Because Connexions software provides a publishing platform that supports “frictionless remix”, its functionality is a good model for the actions that a publishing API for OER should support. With the help of Connexions’ Systems Engineer, we catalogued the data and metadata that is available, the current publishing implementation, and ideas for how to build licensing, versioning, derived copies, and authorship roles into an API. Those details are found on the Roadmap Wiki here.
Connexions’ Google Summer of Code projects were accepted and two students were chosen. : (April 25th on) : Both of Connexions Google Summer of Code projects have the potential to increase OER production in open repositories.
- Creating a Google Docs editor for Connexions would result in a simple pathway for authors to produce content, and the publishing API from this fellowship would allow docs authors to push their content in from wherever they create it.
- The second project, Enhanced Author Profiles and Kudos, is also relevant to API’s for OER, because it will make it much easier for authors to advertise their publication of open education materials from Connexions.

 Sprinting at the Plone East Symposium (May 19-22): We sprinted (communal coding) to extend an existing partial publish implementation in Connexions. The extension allows creation of modules from deposited Word files or CNXML (Connexions semantic document format) files and improves the handling of metadata (title, language, etc). With the help of fellow fellow, Mark Horner, we found and invited Carl Scheffler, whose background is in machine learning, and whose interests include improving education, to participate in the sprint, along with Connexions own Phil Schatz and Ross Reedstrom, with Penn State’s team Mike Halm and Michael Mulich advising. The sprint planning is here and the full description of the day is here.
Sprinting at the Plone East Symposium (May 19-22): We sprinted (communal coding) to extend an existing partial publish implementation in Connexions. The extension allows creation of modules from deposited Word files or CNXML (Connexions semantic document format) files and improves the handling of metadata (title, language, etc). With the help of fellow fellow, Mark Horner, we found and invited Carl Scheffler, whose background is in machine learning, and whose interests include improving education, to participate in the sprint, along with Connexions own Phil Schatz and Ross Reedstrom, with Penn State’s team Mike Halm and Michael Mulich advising. The sprint planning is here and the full description of the day is here.

IMS Learning Impact and an emphasis on phased implementation strategy: (May 16-18) The IMS Learning Impact conference was the perfect place to corner, I mean get advice from, those with experience creating API’s and making pathways between software and services. Many thanks to Chuck Severance, Jeff Kahn, Gerry Hanley, Brad Felix and several folks I met at the conference. These discussions led to a general approval for (minor spoiler alert) SWORD, and a planned phased approach to implementing it in Connexions (sooner is better than complete). A simple first cut at the API and an implementation in Connexions allows us to start building tools that use the API to generate interest and excitement and software that others can use, improve, and copy as well.
Open Repositories 2011: The SWORD Workshop: The Choice Revealed (June 7,8)
After meeting with the SWORD technical team, learning more about the second version of SWORD, and conferring with Connexions’ Systems Engineer, SWORD built on AtomPub became the clear winner among the API servings. (And now that Goldilocks metaphor officially ends.) SWORD is simple, flexible, popular, and has a head start in Connexions where we will test it first. The full reasoning is published in the blog entry before this one and a bit more detailed reasoning here.
Client investigations: Translation tools
So with the choice of SWORD, and V2 in particular, investigating potential clients is in full swing. Translating content allows multilingual domain experts to contribute to OER without creating something from scratch. Siyavula’s translation sprints for the Free High School Science textbooks demonstrate that people who know the subject and the language are willing to help out. Carl Scheffler is investigating a couple of different approaches to translation.
- Using CodeMirror: For geeks unafraid to see XML, this demonstration protects tags so only text gets changed – demo here.
- Using Google Translate Toolkit: Translate Toolkit is designed for all translators and the beginnings of the investigation are described here. Using Translate Toolkit would require a web service that manages various format transformations that are needed.

 The Specification of the API and implementation are underway. The Specification of an OER Publishing API extension of SWORD V2 has begun. The SWORD protocol should work as is, so the extensions should not change the protocol, but rather make use of the natural SWORD flexibility to include extra metadata and return repository specific information. For Connexions, the first phase of implementation of a SWORD V2 service will support creating, updating, publishing, versioning, and deriving copies of modules through the existing editing spaces (to hold the modules as they are being constructed). The following pages show the progress and ongoing work.
The Specification of the API and implementation are underway. The Specification of an OER Publishing API extension of SWORD V2 has begun. The SWORD protocol should work as is, so the extensions should not change the protocol, but rather make use of the natural SWORD flexibility to include extra metadata and return repository specific information. For Connexions, the first phase of implementation of a SWORD V2 service will support creating, updating, publishing, versioning, and deriving copies of modules through the existing editing spaces (to hold the modules as they are being constructed). The following pages show the progress and ongoing work.
