An API for Open Publishing or A Little Plumbing Goes a Long Way
I recently gave an update on my Shuttleworth Foundation Fellowship. My goal for the fellowship is to make it easier to publish open education resources that are adaptable and remixable. My slides for the talk are below.
You can also see me give the talk at OpenEd, but unfortunately some time is wasted on technical difficulties with the projection. Maybe it will give you a laugh.
Background: I spent four years at Connexions, a repository for teaching and learning materials where anyone can publish and anyone can teach, learn, and remix. That experience led me to see the need for a way to push innovation and development into the community beyond the repository. Connexions provides services for storing, retrieving, and remixing educational content, but trying to provide all of the other services that educators and learners need directly within the repository just doesn’t scale.
 The need for an ecosystem of tools and services: To maximize the benefit of the materials, we need editors to create the content, converters to take our existing content and create remixable versions, tools for rating, reviewing, and discussing the content, services for printing, services for packaging for learning management systems, adaptive learning environments that delivery and coach, alignment tools, and lots of things that have yet to be invented. That innovation and creativity needs to occur in an open ecosystem around learning repositories.
The need for an ecosystem of tools and services: To maximize the benefit of the materials, we need editors to create the content, converters to take our existing content and create remixable versions, tools for rating, reviewing, and discussing the content, services for printing, services for packaging for learning management systems, adaptive learning environments that delivery and coach, alignment tools, and lots of things that have yet to be invented. That innovation and creativity needs to occur in an open ecosystem around learning repositories. 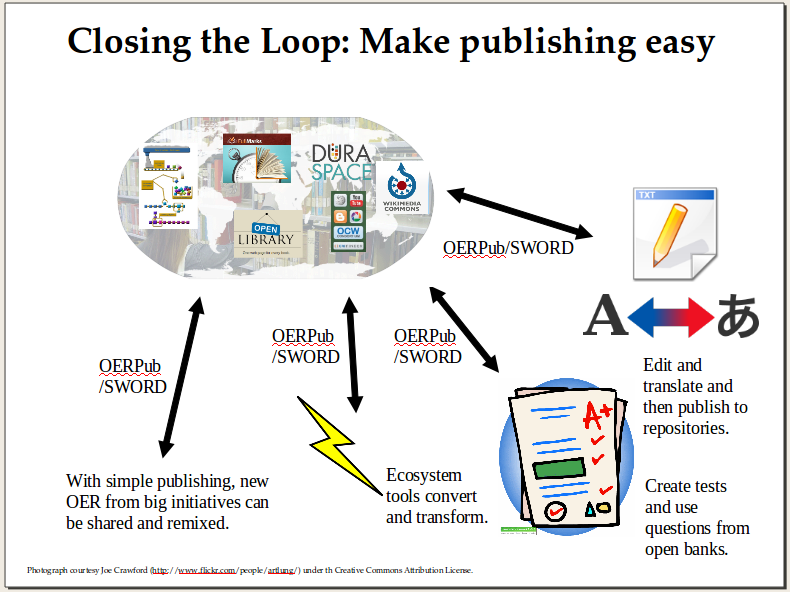 Step 1 (Done). Closing the loop: Making publishing easier. So the first step in the fellowship was to choose and adapt an API (Application Programming Interface) for publishing to Open Repositories. This step involved research, advice gathering, and then specification writing.
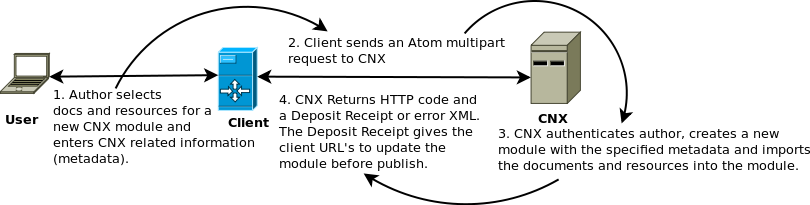
Step 1 (Done). Closing the loop: Making publishing easier. So the first step in the fellowship was to choose and adapt an API (Application Programming Interface) for publishing to Open Repositories. This step involved research, advice gathering, and then specification writing.We now have a specification called OERPub that is based on SWORD which is in turn based on the blog publishing API, AtomPub. A couple other blog entries (one, two) discuss SWORD (Simple Webservice Offering Repository Deposit) but in a nutshell SWORD is simple, has a large community of implementors, and gets the job done for publishing learning resources as a unit with educational metadata that applies to the whole resource. SWORD had been implemented mainly in institutional archive repositories rather than for learning resource repositories, so our adaptations to SWORD extend its usage strategically for OER. OERPub makes the API relevant to open education and good for adaptation and remix. OERPub adds recommended educational metadata, explicit mechanisms for creating new versions and creating adaptations (derived copies), and workflow and error handling for handling repository specific publication and licensing requirements. The European education agency, JISC, that sponsored the SWORD development has helped fund an OERPub client – described in Step 3. The SWORD community has offered to host the new OERPub specification and help publicize our efforts.
Step 2 (Done for Modules). Implementing publishing in Connexions. The second step, was to implement OERPub in Connexions (cnx.org) to provide a concrete test of the new specification and provide the first-ever programmatic pathway to create, edit, and publish content in Connexions. We chose Connexions for the first implementation of OERPub because anyone can publish to Connexions (so the benefits are broadly available) and Connexions content is remixable, which is the kind of content that we are trying to increase. This step, implementing the API, is akin to building some very handy plumbing. The implementation in Connexions for creating, editing, and publishing modules rolled out in the first week in October.
- Detailed Implementation Specification for OERPub in Connexions
- Documentation of the OERPub API on Connexions developer site.
Step 3 (In Progress). Community Prototypes leading to Massive Content Enabling. Step three is to put this all together and work with content producers and software developers to build creation, editing, and translating tools that help authors publish great content and lead to massive increases in adaptable learning content. This is the “glass of water” step that the plumbing is there to deliver. I am planning to write future posts about the ones we have planned and some early stage ideas. Live samples are coming soon. Below are a few we are actively working on.
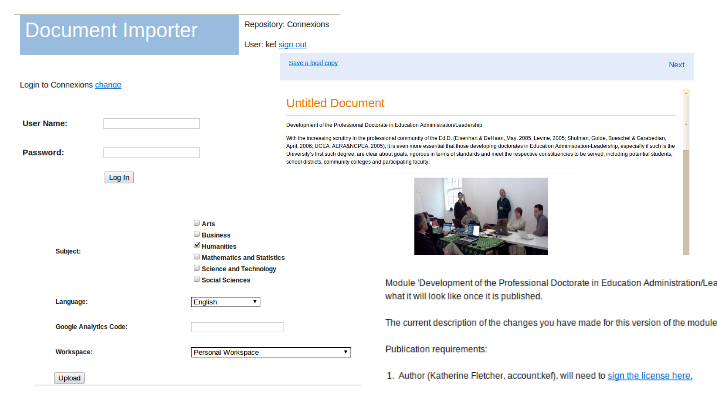
- Prototype Massive Content Enabler (Code on Github). This importer currently takes Word documents, Open Office/ Libre Office documents, Connexions documents, Google Docs, and some HTML and blog entries. It transforms them if needed into a remixable XML format (CNXML), shows a styled preview, and then lets authors upload and publish to OER repositories (currently Connexions).
- Components of this tool can be used on their own, like the previewer (code on github). The converters can all also be used on their own, and more importantly, improved independently.
- Translation. Connexions content CC-By licensing makes translations a simple matter of fluency. We are working on a tool that lets translators select a Connexions module and the tool derives a copy, gets the content, retrieves a machine translation candidate (if requested), edit the translation, and publish the new module with links to the original — all using the OERPub API.
- Batch Operations: The API also provides immediate benefits for experts that are comfortable writing scripts that make repeated operations fast and efficient. The Washington State Board of Community and Technical Colleges Open Course Library has produced 42 courses for high-enrollment, high-impact community and technical college courses. Each course is represented by a Connexions module that showcases the syllabus, downloads for learning mangament systems (LMS’s) and pointers to the Saylor Foundation versions of the courses when available. These Open Course Library modules were created using the new OERPub API. Upcoming batch scripting projects will publish translations for existing content and link them to their original-language sources, and will produce a tool for textbook publishers to migrate content from a development server to the live server.